Функция дедупликации (SmartDedupe) в системах хранения данных Huawei используется для оптимизации использования дискового пространства и снижения нагрузки на хранилище. Дедупликация позволяет определить и удалить дублирующиеся блоки данных, сохраняя только одну копию каждого блока.
Процесс дедупликации начинается с разбиения данных на блоки фиксированного размера. Затем каждый блок анализируется и сравнивается с уже существующими блоками данных. Если блок уже существует, то вместо создания новой копии он заменяется ссылкой на существующий блок. Это позволяет существенно сократить объем хранимых данных.
Дедупликация может быть применена к различным типам данных, включая файлы, виртуальные машины, базы данных и другие. Она особенно эффективна в случае, когда в хранилище хранятся множество копий одних и тех же данных, например, виртуальных машин с одинаковыми операционными системами или дублирующихся файлов.
Функция дедупликации в системах хранения данных Huawei может быть настроена для автоматического выполнения в фоновом режиме или вручную, в зависимости от потребностей и предпочтений пользователя. Она помогает снизить потребление дискового пространства, улучшить производительность хранилища и уменьшить затраты на обслуживание и расширение хранилища
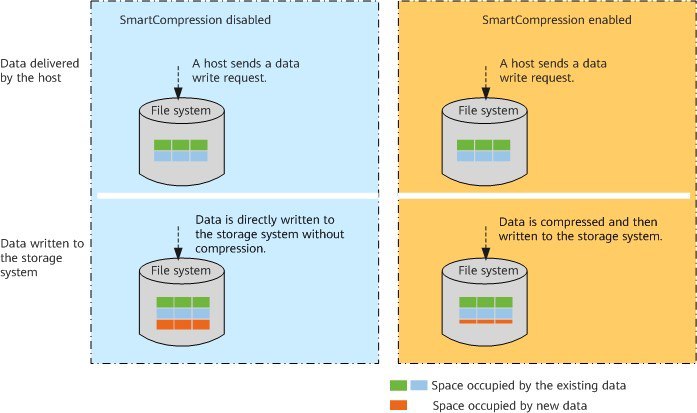
Функция SmartCompression (умное сжатие) в системах хранения данных Huawei используется для сжатия данных, что позволяет сэкономить дисковое пространство и улучшить производительность хранилища.
SmartCompression основана на алгоритмах сжатия данных, которые анализируют и оптимизируют структуру данных перед сжатием. Это позволяет достичь более эффективного сжатия и уменьшить объем хранимых данных без потери качества.
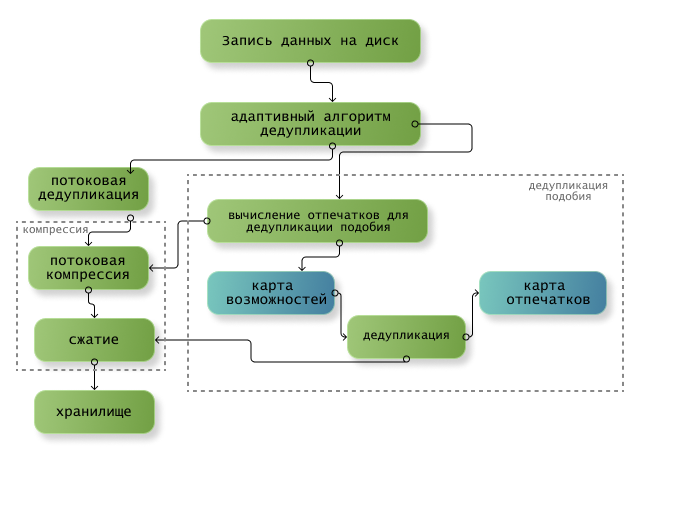
В системе хранения предусмотрена политика адаптивной дедупликации, сочетающая обычную дедупликацию и дедупликацию на основе подобия. Система адаптивно выполняет дедупликацию и сжатие на основе характеристик служебных данных в различных сценариях. Адаптивная дедупликация и сжатие максимизируют коэффициент сокращения данных.
На рисунке показан общий принцип обработки:
Основные концепции SmartDedupe и SmartCompression заключаются в следующем:
- Размер блока данных дедупликации: определяет степень детализации данных, которые будут дедуплицированы в системе хранения.
- Размер блока данных сжатия: определяет степень детализации данных, которые будут сжаты в системе хранения.
- Дедупликация на основе подобия: система делит данные на блоки фиксированного размера и анализирует сходство между блоками. Затем система выполняет дедупликацию идентичных блоков данных и выполняет комбинированное сжатие похожих блоков данных.
- Отпечаток: отпечаток представляет собой двоичное число фиксированной длины. В системе хранения все сопоставления между отпечатками блоков данных и местами хранения данных хранятся в таблице отпечатков.
- Подобный отпечаток (SFP): определяет сходство данных. Если две части данных имеют один и тот же SFP, содержимое этих двух частей данных будет частично или полностью одинаковым.
- Градиентный отпечаток (GFP): часть данных может быть похожа на несколько частей других данных и, следовательно, может иметь несколько SFP. Чтобы во время дедупликации преимущественно обрабатывались отпечатки с высокой степенью сходства, система также записывает GFP для описания сходства данных при расчете SFP.
- Карта возможностей: сохраняет отпечатки и информацию о местоположении блоков данных, а также идентифицирует горячие данные
- Побайтовое сравнение: когда система хранения ищет повторяющиеся блоки данных, она сравнивает отпечатки блоков данных. Если отпечатки совпадают, система побайтно сравнивает блоки данных.
- Метаданные дедупликации: сохраняет информацию о дедупликации. Например, метаданные сохраняют информацию об отпечаткахблоков данных и местах хранения данных после выполнения дедупликации.
На рисунке показан процесс дедупликации по принципу подобия:
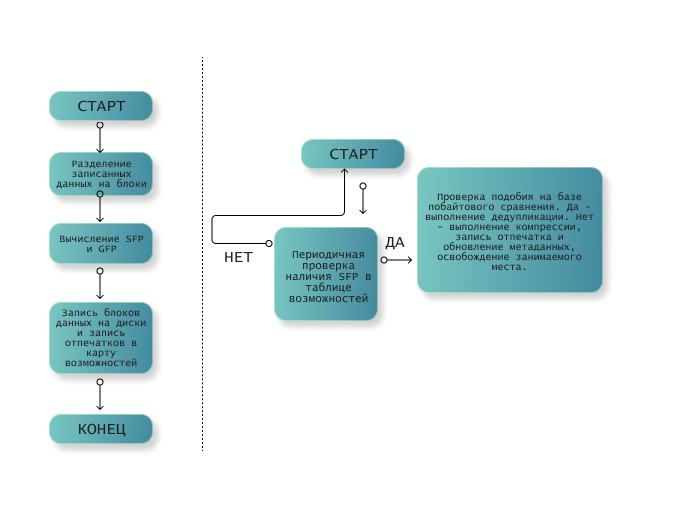
Шаг 1:
Шаг 2:
| Имя файловой системы | Существующие блоки данных | Характеристики нового блока данных |
| File system 1 | Блоки A, B, и C | SFP блока данных J хранится в таблице возможностей. Блок данных J совпадает с блоком данных E при побайтовом сравнении. SFP блока данных K хранится в таблице возможностей. Блок данных K отличается, но подобен блоку данных I при побайтовом сравнении. Отпечаток блока данных L не найден в таблице возможностей. |
| File system 2 | Блоки D, E, и F | - |
| File system 3 | Блоки G, H, и I | - |
На рисунке показаны результаты дедупликации при включенном и выключенном алгоритме SmartDedupe:

SmartCompression